Internal Agent Skill Registries — and Why You Must Scan Them with SkillSpector
Internal Agent Skill Registries — and Why You Must Scan Them with SkillSpector
In an earlier post I laid out a simple stack for working with AI agents: MCP Servers give an agent capability (what it can reach and do), Agent Skills give it behaviour (how it should do things), and APM handles distribution (getting those skills shared and installed consistently). Together they turn a general-purpose assistant into something that actually fits the way your team and organisation.
That post ended on distribution. This one starts where it gets uncomfortable:
The moment skills become something you share and install, you have a software supply chain — and right now, almost nobody is treating it like one.
A skill is not a passive document. It is a set of instructions that steers an agents behaviour. Some skills ship small scripts that an agent can run on your machine. So a skill you install is, in effect, behaviour you are granting to something with real access. Where that behaviour comes from, and whether anyone has checked it, suddenly matters a great deal.
Two things follow from that, and they are the subject of this post:
- You need an internal registry for your skills.
- You need to security-scan everything that goes into it.
How most teams "manage" skills today
Be honest about the current state of things. Someone finds a useful skill in an external GitHub repo, a blog post, or a colleague's Slack message. They copy the folder into their project. It works, so they move on. A week later someone else copies a slightly different version into a different repo. Nobody is quite sure which copy is the canonical one, who wrote the original, or what changed between them.
This is exactly how JavaScript worked before npm and Python before pip — except with one important difference. A copied library does roughly what its function names say. A copied skill is natural-language instruction handed to an agent.
The blast radius is bigger and the contents are far easier to tamper with, because "malicious" can be a single sentence buried in a markdown file. Which can also be hidden in plain sight.
Copy-paste does not scale, it loses all provenance, and it has no gate. That is the problem an internal registry solves.
What an internal skills registry actually is
An internal skills registry is simply one trusted, version-controlled place where your approved skills live, and the place every team installs from — instead of from the wild.
It is the same idea as a private npm registry, an internal PyPI, or an artifact repository like Artifactory. Most organisations would never let developers pip install straight from a random author into production without it passing through something they control. A skills registry brings that same discipline to agent behaviour.
What you get from having one:
- A single source of truth - One canonical version of each skill, not five drifting copies.
- Review before entry - Nothing becomes "approved" until a human (and, as we will see, a scanner) has looked at it.
- Versioning and pinning - Teams can depend on a known version and upgrade deliberately, rather than silently inheriting whatever someone edited last.
- Provenance - You know where every skill came from and what changed, because it all goes through pull requests.
- Discoverability - People can find the skill that already exists instead of writing a worse one from scratch.
- Bundling - Related skills can be grouped for a team or a tool, so onboarding is one install command rather than a scavenger hunt.
- Reusability- Skills can be reused and shared between engineers in an team/organisation.
None of this is new. It is the boring, proven governance we already apply to code dependencies.
What it looks like in practice
My own registry is just a public Git repository. Skills live under .github/skills/, each one a SKILL.md with a little YAML frontmatter and any supporting files. They are grouped into APM packages so anyone can pull a themed bundle in one go, and a CI workflow validates every change. Installing a bundle is a single command:
apm install okaneconnor/agent-skills/packages/security
The structure is deliberately unremarkable:
agent-skills/
├── apm.yml # root manifest, wires the bundles together
├── packages/ # themed bundles (security, coding, diagramming…)
└── .github/
├── skills/ # the skills themselves, one folder each
└── workflows/ # CI: validate + security-scan every change
The point is not the exact layout. The point is that there is a layout — one place, under version control, with a front door that every change has to walk through.
And once you have a front door, the obvious question is: what is stopping someone from walking a malicious skill straight through it?
Or if we are using external skills created from another person/repository. How can we know and trust this?
Why a skill is a genuine attack surface
It is tempting to think "it's just a markdown file, what's the harm?" Here is the harm, plainly.
A skill is read by an agent and treated as trusted instruction. That gives an attacker several ways in:
- Prompt injection. Hidden or cleverly-worded instructions that tell the agent to ignore its rules, leak context, or take an action the user never asked for.
- Data exfiltration. A skill that nudges the agent to send file contents, secrets, or conversation history to an external endpoint "for logging".
- Tool poisoning. A skill that quietly redefines how an MCP tool should be used, steering the agent towards a harmful call while looking helpful.
- Malicious scripts. Many skills ship helper scripts. Those run on a developer's machine or in CI, with whatever access that environment has.
The unsettling part is how normal a malicious skill can look. There is no obviously dangerous eval() to spot — it can be one persuasive paragraph. A human reviewer skimming a long markdown file will miss it, and "trust the author" is not a security control. You need something that reads every skill specifically looking for these patterns. That is what SkillSpector is for.
SkillSpector: a security scanner built for skills
SkillSpector is an open-source (Apache-2.0) tool from NVIDIA that does one job well: it scans an agent skill for vulnerabilities, malicious patterns, and security risks before you install it. It ships around 68 detection patterns across 17 categories, covering exactly the risks above — prompt injection, data exfiltration, MCP tool poisoning, suspicious scripts, and more.
You point it at a skill folder, a single file, a Git repo, or a zip:
skillspector scan ./my-skill/
It works in two layers. A fast static layer runs locally with no credentials, using YARA signatures and rule-based checks — this is deterministic and free. On top of that, an optional LLM layer reads the skill semantically and catches the subtler, language-based tricks that signatures cannot.
You can run static-only with --no-llm when you want speed and reproducibility, and turn the LLM layer on when you want depth.
The output is the bit that makes it useful in automation. Every scan produces a risk score from 0–100, a severity, and a clear recommendation:
| Score | Severity | Recommendation |
|---|---|---|
| 0–20 | LOW | SAFE |
| 21–50 | MEDIUM | CAUTION |
| 51–80 | HIGH | DO_NOT_INSTALL |
| 81–100 | CRITICAL | DO_NOT_INSTALL |
It can emit that as a human-readable report, as JSON, or as SARIF, and — crucially — it sets an exit code you can gate on: 0 for a risk score of 50 or below, 1 for anything above, 2 for an error. That tiny detail is what lets you wire it into a pipeline and have it block bad skills automatically rather than just printing a warning nobody reads.
Why everyone should be using it
You would not merge a new code dependency with no scanning at all. Skills deserve more scrutiny, not less, because they directly steer an agent that can act on your behalf. SkillSpector is free, open source, runs offline if you want it to, and takes minutes to set up. There is genuinely no good reason to install skills blind when a check this cheap exists. Run it on skills before you adopt them, and run it on your own before you publish them.
Putting the two together: scanning at the registry's front door
A registry gives you a single place every skill passes through. SkillSpector gives you a check that can pass or fail a skill. Combine them and you get the thing you actually want: a registry that automatically refuses to accept an unsafe and unchecked skill.
This is exactly what I wired into my own registry, and the flow is simple:
- Someone opens a pull request to add or change a skill.
- A GitHub Action installs SkillSpector and scans only the skills that changed in that PR.
- If any skill scores above 50 (
DO_NOT_INSTALL), or the scan errors, the check fails and the PR is blocked. - Either way, the result is posted back as a clean summary — on the pipeline and as a comment on the PR itself.
The gate itself is just the tool's exit code doing its job:
# Per changed skill: one scan, exit code is the verdict
skillspector scan "$skill" --format json --output "reports/$name.json"
# exit 0 -> risk <= 50 (pass) exit 1 -> risk > 50 (block) exit 2 -> error (block)
And the reviewer does not have to go digging through logs — the verdict lands right on the pull request:
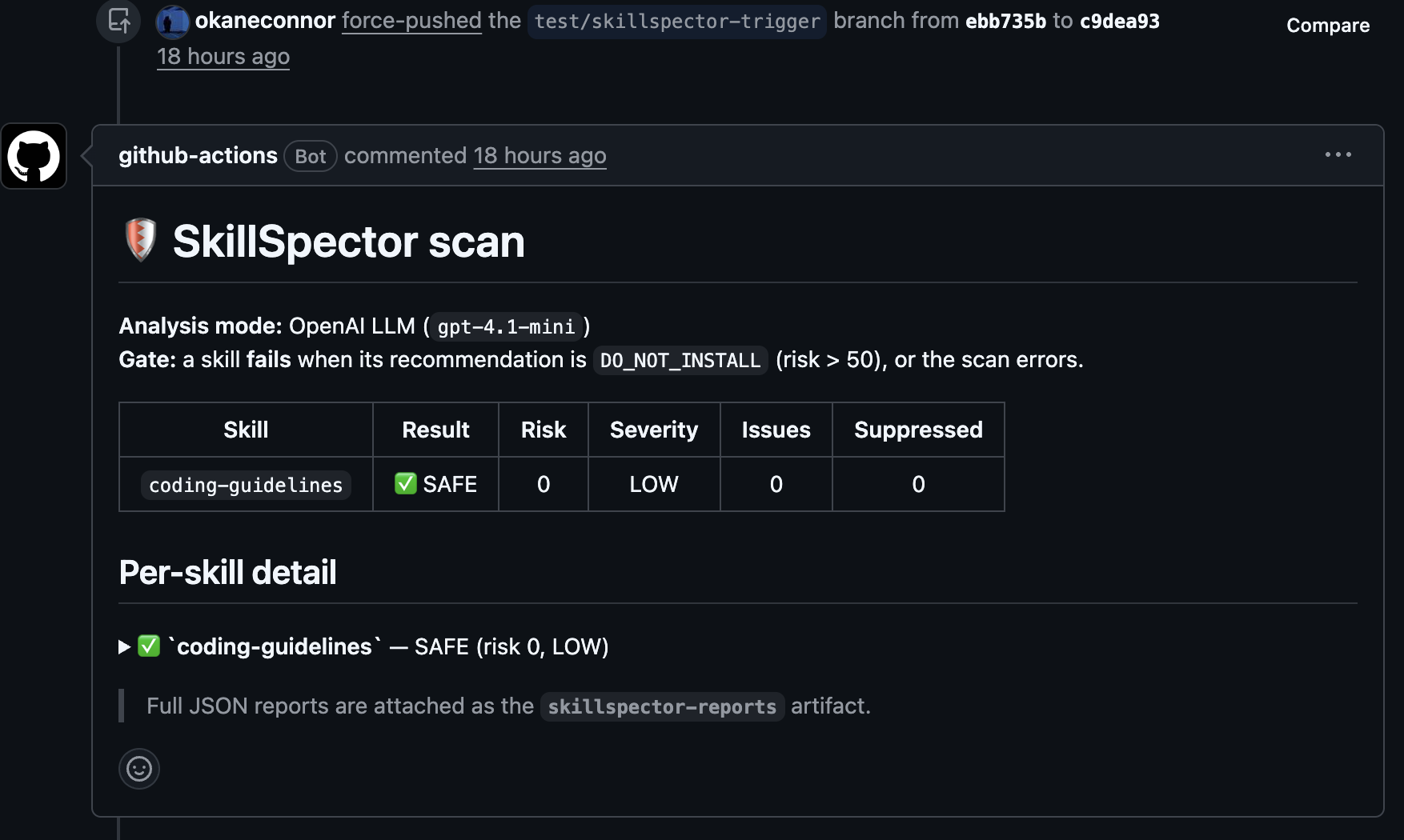
That is the whole idea: a malicious or risky skill cannot quietly become "approved", because the only way into the registry is through a gate that read it properly first. Approval stops being "the author seemed trustworthy" and becomes "it passed review and it passed the scanner".
How to start — without boiling the ocean
You do not need a platform team or a big project to get most of this value. A realistic path:
- Pick one repo to be the registry. A single Git repository that becomes the one place approved skills live.
- Require pull requests. Every skill change goes through review. No direct pushes.
- Add SkillSpector to CI. Scan changed skills on every PR and block on
DO_NOT_INSTALL. Start in static-only mode — it needs no secrets — and add the LLM layer later. - Publish the result on the PR. Make the verdict visible so reviewers and authors both see it.
- Distribute with APM. Let teams
apm installfrom the registry instead of copying folders around.
Each step is independently useful, and you can stop at any point and still be better off than copy-paste.
What this is, and what it is not
Worth being honest about the edges:
- A scanner is a layer, not a guarantee. SkillSpector dramatically raises the bar, but security is defence in depth. Human review still matters.
- The LLM layer is probabilistic. It catches things signatures miss, but it is not infallible. Treat the static layer as your deterministic floor and the LLM layer as a valuable bonus.
- Pin what you depend on. I run SkillSpector from its latest version for freshness, which means its rules can evolve under me. For a hard merge gate where you want total reproducibility, pin the version and upgrade deliberately.
None of these undermine the approach. They are the difference between "much safer" and "complacent", and the honest framing keeps you in the first camp.
The takeaway
The stack from the previous post had three layers. Securing it adds a fourth — and it is the one that lets you actually trust the other three.
| Layer | Technology | Answers |
|---|---|---|
| Capability | MCP Server | What can the agent access and do? |
| Behaviour | Agent Skill | How should the agent do it? |
| Distribution | APM | How do skills get shared and installed? |
| Trust | Registry + SkillSpector | Is this skill safe to install? |
Agent skills are quietly becoming a dependency like any other — except this dependency is behaviour handed to something with real access to your systems. Treat it with the same seriousness you already give your code supply chain: keep skills in one governed registry, make every change go through review, and put an automated security scanner at the door so an unsafe skill can never walk in unnoticed.
The full registry, including the SkillSpector GitHub Action described here, is open source: github.com/okaneconnor/agent-skills. Clone it, point SkillSpector at a skill, and you will have a security gate for your agent behaviour running in an afternoon.